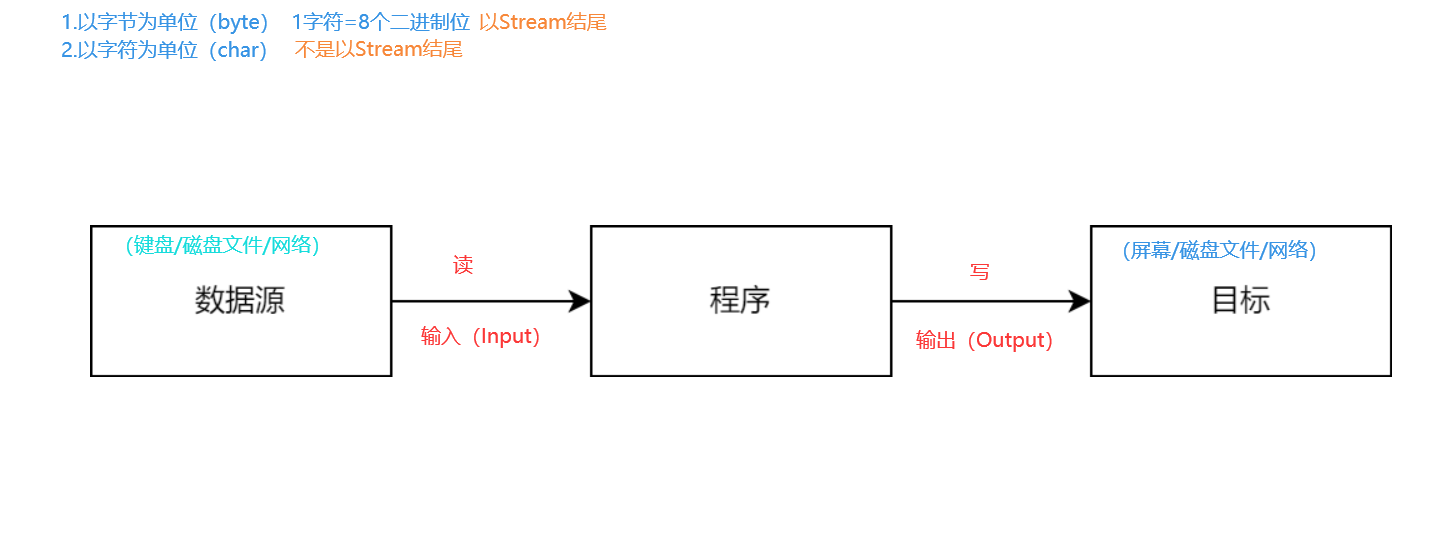
- 数据的读写:
字节流:以字节为单位(byte)以Stream结尾
字符流:以字符为单位(char)不以Stream结尾
2.FileInputStream(三个参数:string name(文件的全路径)/File file(文件对象)/FileDescriptor)
实例TestByteStream.java
[qzdypre]
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class TestByteStream {
public static void main(String[] args) throws IOException {
InputStream in=new FileInputStream("data/data.txt");//打开文件
int ch;
while((ch=in.read())!=-1){ //读写文件
System.out.print((char) ch);
}
in.close(); //关闭文件
}
}
[/qzdypre]
int read( ): 从数据源读取一个字节,返回该字节对应的整数;若无数据可读,则返回-1
三部曲:1.打开文件(line 8) 2.读写文件(line 10) 3.关闭文件(line 13)
更多详细参数查看群文件IO————IO.docx
int read(byte[ ] buf): 试图从数据源读取buf.length个字节,并存入buf数组,返回实际读取的字节数;若无数据可读,则返回-1
[qzdypre]
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class TestByteStream {
public static void main(String[] args) throws IOException {
InputStream in=new FileInputStream("data/data.txt");//打开文件
int count;
byte[] b=new byte[10];
while((count=in.read(b))!=-1){ //读写文件
System.out.print(new String(b,0,count));
}
in.close(); //关闭文件
}
}
[/qzdypre]
data.txt文件如下:

line12中指定了从第0位读取到count结束,若不指定读取数组的长度(即上方line12中的语句为System.out.print(new String(b)); ),则会导致多余未被冲掉的数组被输出
示意如下:
第一次读取的十位:ABCDEFGHIJ
第二次读取的十位:KLMNOPQRST
第三次只能读取八位:UVWXYZ\r\n
第三次读取的八位冲去了第二次读取的前八位(即第二次读取的第九位和第十位(ST)被保留了下来)所以输出的时候除了输出data.txt中的字符外,也会输出ST。
运行结果如下:

int read(byte[ ] buf, int offset, int len): 试图从数据源读取len个字节,存入buf数组从buf[offset]开始的元素中,返回实际读取的字节数;若无数据可读,则返回-1
3.输出流:
[qzdypre]
OutputStream out= new FileOutputStream("data/data2.txt");
[/qzdypre]
将文件输出到data2.txt中(有则覆盖原文件,无则自动创建一个新文件)
但是如果在参数后加了“true",则会将输出的文本追加在原文本的后方,而不是覆盖原文件!
要记得在输出流的最后也要加上关闭文件的操作,无论是输入流还是输出流都要关闭。
[qzdypre]
in.close(); //关闭文件
out.close(); //关闭文件
[/qzdypre]
输出文件(复制)的参数:
实例Copy.java
[qzdypre]
import java.io.*;
public class Copy {
public static void main(String[] args) throws IOException {
InputStream in=new FileInputStream("原文件的路径(注意不能是一个目录)");
OutputStream out=new FileOutputStream("输出文件的路径");
int count;
byte[] buf=new byte[1024];
long start=System.currentTimeMillis();
while((count=in.read(buf))!=-1){
out.write(buf,0,count);
}
long end=System.currentTimeMillis();
in.close();
out.close();
System.out.println(end-start);//计算从开始到结束的时间(单位:毫秒)
}
}
[/qzdypre]
(line11)通过对buf数组大小的调整,数值越大则拷贝速度越快(读写次数越少,每次读写的数据量越大),要注意的是InputStream和OutputStream不能用来拷贝目录。
关于currentTimeMillis(line12和16):为了便于记录某个方法块的执行时间,通常都会在代码块的执行前和执行后各标记一个时间,取两个时间差。
currentTimeMillis()这个方法得到的是自1970年1月1日零点到目前计算这一刻所经历的的毫秒数,注意这里返回值为long型,至于为什么不是int,因为int已经存不下了
[qzdypre]out.flush()[/qzdypre]
将缓冲区的数据刷新,立刻写入目标文件,然后将缓冲区清空

文章评论